TensorFlow, inizialmente sviluppato da Google e successivamente rilasciato in open source è una delle piattaforme di Machine Learning più utilizzate e flessibili grazie all’utilizzo di API di alto livello, fino al deployment su browser o device.
TensorFlow, inizialmente sviluppato da Google e successivamente rilasciato in open source è una delle piattaforme di Machine Learning più utilizzate e flessibili grazie all’utilizzo di API di alto livello, fino al deployment su browser o device.
Sono presenti diverse librerie con la gestione della distribuzione e di particolare interesse sono quelle più leggere per il mobile e l’IoT.
Viene utilizzato per il riconoscimento vocale (voice recognition), la sentiment analysis, il riconoscimento della lingua, language detection, il riepilogo di testi (text summarisation), il riconoscimento di immagini, il rilevamento dei video, le serie temporali, ecc.
Iniziamo ad usare TensorFlow
Andiamo sulla home page del progetto e scegliamo [Inizia con TensorFlow]
Entriamo nella pagina di overview e scegliamo il percorso “per principianti”.
Se non hai mai utilizzato il Machine Learning puoi seguire questo percorso suddiviso in questi passi:
- Programmazione
- Matematica e statistica
- Teoria del Machine Learning
- Costruzione di un progetto
Questa è la pagina da cui partire.
Esempio di applicazione del ML con TensorFlow
un esempio tipico di utilizzo del ML è la classificazione.
Si veda questo esempio è una classificazione di base: classifica le immagini di abbigliamento
L’esempio si chiama: classification.ipynb
Nota: cosa sono i file in formato .ipynb.Un file IPYNB è un documento di quaderno utilizzato da Jupyter Notebook, un ambiente di calcolo interattivo progettato per aiutare gli scienziati a lavorare con il linguaggio Python e i loro dati. Contiene tutto il contenuto della sessione dell’applicazione web Jupyter Notebook, che include gli input e gli output di calcoli, matematica, immagini e testo esplicativo. I file IPYNB possono essere esportati nei formati .HTML , .PDF , reStructuredText e LaTeX.
I documenti del notebook IPYNB sono archiviati nel formato di testo semplice JSON, il che rende più facile la loro condivisione con i colleghi e il controllo delle versioni. Inoltre i documenti del notebook IPYNB disponibili da un URL accessibile pubblicamente possono essere condivisi utilizzando il Jupyter Notebook Viewer con altri colleghi senza richiedere che installino Jupyter Notebook sui loro computer.
Selezionare la lingua inglese
Le fasi sono le seguenti:

Fashion-MNIST dataset è un set di trainingi di Zalando costituito da +60.000 esempi e +10.000 elementi di test. Ogni immagine è costituita da 28×28 pixel in scale di grigio. Ogni elemento ha 10 classi di etichetta.
Fashion-MNIST può essere trovato a questo indirizzo
Si possono esplorare i dati con il tasto [Explore in Know Yuor Data] oppure visitare l’home page su Github
Cliccare su [Run in Google Colab]

A questo punto i diversi blocchi di codice diventano eseguibili e possiamo cliccare sul tasto di RUN. Quando un blocco è eseguito apparirà la spunta verde.

Un esempio pratico
Proviamo a realizzare una classificazione di capi d’abbigliamento (Basic classification: Classify images of clothing)
La pagina del progetto è questa.
Questa guida utilizza tf.keras che è un set di API di alto livello per costruire ed addestrare un modelli in. TensorFlow. Se vogliamo conoscere come funziona lo strato interno di Keras possiamo utilizzare Google Colab con il file sequential_model.ipynb.
Sempre su Keras sono disponibili alcuni esempi in 3D. Bisogna prestare attenzione alla dimensione e complessità dei dataset considerando che alcuni esempi (come 3D_image_classification) possono durare anche molti minuti di elaborazione. Bisogna fare attenzione quindi di avere una applicazione che utilizzi i crediti temporanei e non superi i limi di capacità di calcolo e temporali del pacchetto gratuito.
![]()
Loading the dataset returns four NumPy arrays:
- The
train_imagesandtrain_labelsarrays are the training set—the data the model uses to learn. - The model is tested against the test set, the
test_images, andtest_labelsarrays.
Le immagini sono matrici (array) 28×28 NumPy, con un valore di pixel compreso tra 0 e 255. Le label sono un array di interi compreso tra 0 e 9.with pixel values ranging from 0 to 255. The labels are an array of integers, ranging from 0 to 9.
A questi valori corrispondono le classi di abbigliamento rappresentate:
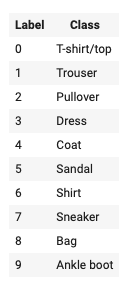
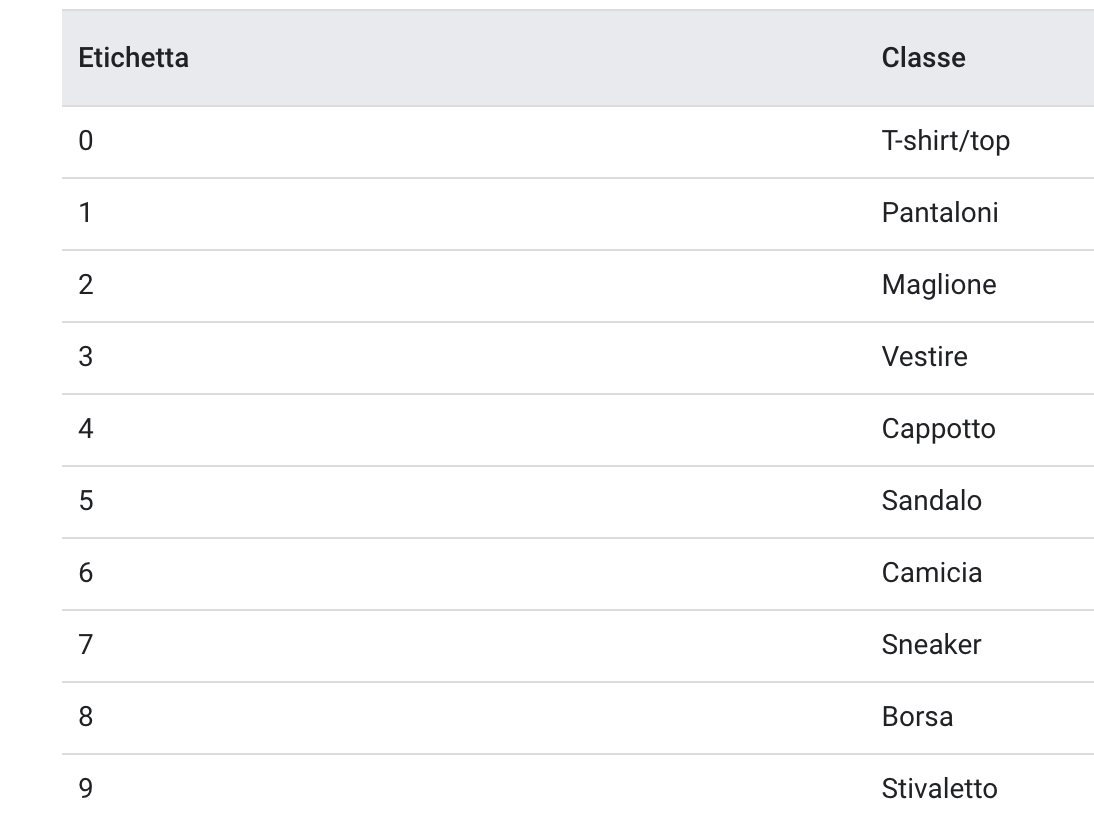
NumPy is è un pacchetto fondamentale per il calcolo scientifico in Python. Si tratta di una libreria che consente la gestione di multidimensional array object, vari oggetti derivati (tra cui masked arrays e matrici), ed un assortimento di routine per accelerare le operazioni su array, incluse funzioni matematiche, logiche, di shape manipulation, sorting, selecting, I/O, trasformazioni di discrete di Fourier, algebra lineare, operazioni statistiche la simulazione della casualità, ecc.